Enterprise, Growth Boards, In Practice, Startups12 months agoThe Challenge of Entrepreneurial Leadership
Enterprise, Growth Boards, In Practice1 year agoFive Big Mistakes to Avoid When Managing an Innovation Portfolio
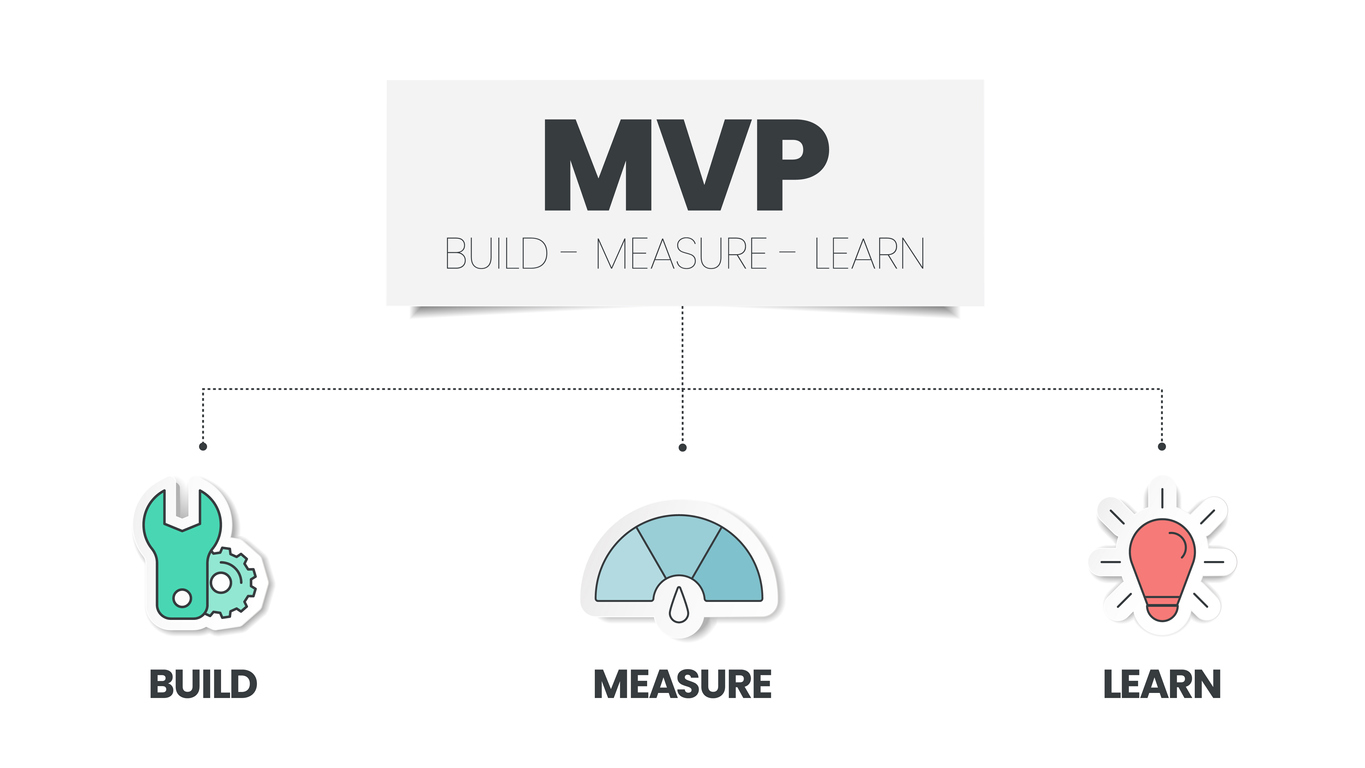
Enterprise, In Practice, Startups1 year ago4 Misapplications of The Lean Startup and How You Can Avoid Them